
CSAT and DSAT: A CXOs Guide to Driving Growth
Most leadership teams already track customer satisfaction. Far fewer treat dissatisfaction as an equally valuable signal. That gap matters because in Indian customer service, up to 80% of organisations use CSAT, while DSAT is still less standardised, even though it is often the faster way to isolate operational pain points and service failures in the WNS perspective on customer feedback.
For a board, that changes the discussion. CSAT and DSAT aren't reporting lines for separate teams. They are one management system. CSAT tells you where experience is holding. DSAT shows where trust, revenue, and efficiency are leaking. Used together, they let leaders decide where to automate, where to redesign workflows, and where to intervene before a poor interaction spreads across channels, agents, and business units.
Table of Contents
- Introduction Why CSAT and DSAT Are Your Most Critical Growth Levers
- CSAT vs DSAT A Unified View for Strategic Insight
- How to Measure and Report on CSAT and DSAT
- Industry Benchmarks and Common Strategic Pitfalls
- Actionable Playbooks to Improve CSAT and Reduce DSAT
- Amplifying Results with DialNexa Voice AI
- Frequently Asked Questions for CX Leaders
Introduction Why CSAT and DSAT Are Your Most Critical Growth Levers
A single customer interaction can affect retention, cross-sell potential, collections, and brand trust at the same time. Yet many leadership teams still review CSAT and DSAT in separate dashboards, owned by separate functions, with separate action plans. That reporting design weakens decision-making.
The stronger approach is to treat satisfaction and dissatisfaction as one operating system for customer experience. CSAT shows where service is meeting expectations at scale. DSAT isolates the points where value leaks out through avoidable friction, repeat contacts, poor handoffs, or delayed resolution. Read together, they tell leaders which journeys protect revenue and which ones put it at risk.
That distinction has direct commercial consequences in India. In BFSI, a dissatisfied service caller may also be a customer less likely to renew, repay on time, or buy an additional product. In EdTech, poor counselling or support interactions can depress conversion and increase refund pressure. In real estate and e-commerce, one broken follow-up flow can reduce both trust and lead quality. Customer feedback is not only a service metric. It is an indicator of conversion efficiency, cost to serve, and future revenue quality.
Board view: CSAT identifies where delivery is working well enough to scale. DSAT identifies where process failure is expensive enough to fix first.
For this reason, csat and dsat deserve executive ownership. Once both metrics are reviewed together across operations, quality, product, and automation, feedback stops functioning as a monthly scorecard. It becomes a management input for prioritising workflow fixes, improving first-contact resolution, and deciding where Voice AI can reduce friction while increasing conversion. That is how contact centres shift from reporting on experience to shaping growth.
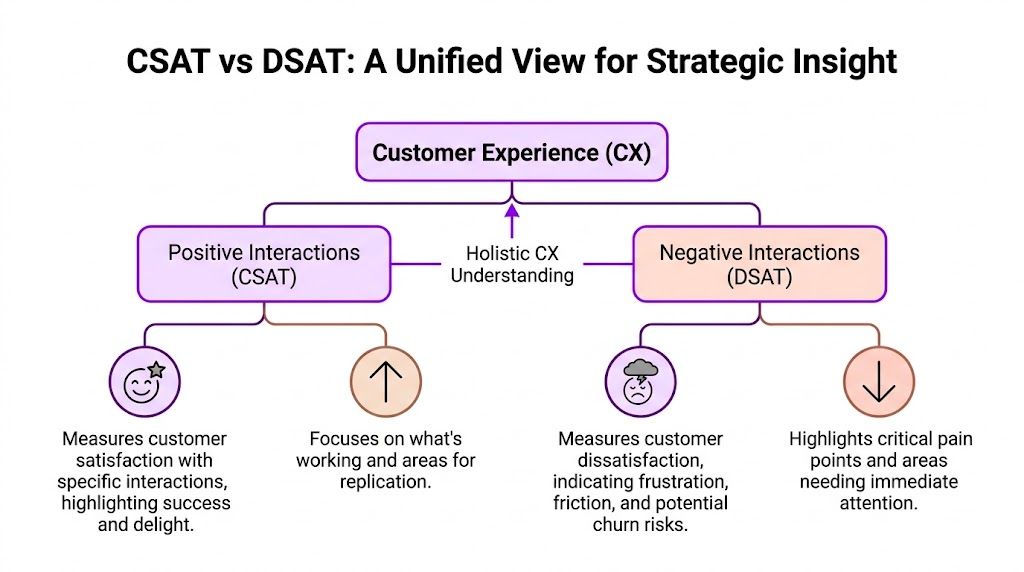
CSAT vs DSAT A Unified View for Strategic Insight
A board reviewing customer feedback needs more than a high-level score. It needs a way to separate broad approval from concentrated operational risk, then connect both to cost, retention, and revenue.
Why one metric can distort the picture
CSAT captures the share of customers who report a satisfactory interaction. It is useful for identifying where service delivery is consistently meeting expectations.
DSAT serves a different purpose. It isolates the customers who experienced enough friction to register a negative outcome. That makes it a sharper signal for service failure, workflow weakness, and breakdowns that are expensive to ignore.
Read separately, these metrics can mislead. A strong CSAT score can hide a small but financially significant pocket of dissatisfied customers, especially in businesses where one failed interaction leads to churn, abandonment, refund pressure, or repeat contact. A low DSAT score can also create false comfort if the survey is poorly timed or misses customers who dropped out before responding.
The strategic value comes from reading both metrics together.
CSAT shows where the model is working well enough to scale. DSAT shows where the model is failing badly enough to require intervention. Used as one system, they help leadership decide where to standardise, where to redesign, and where automation can remove friction without damaging trust.
A board-level model for interpreting both scores
The pairing is most useful when leadership stops asking whether experience is "good" and starts asking where experience quality is uneven.
| Reading pattern | What it usually indicates | Strategic implication |
|---|---|---|
| High CSAT, low DSAT | Delivery is stable across most interactions | Scale winning scripts, processes, and agent behaviours |
| High CSAT, visible DSAT clusters | Averages are masking specific journey failures | Segment by journey stage, issue type, region, language, and channel before setting priorities |
| Mid CSAT, high DSAT | Service friction is affecting a meaningful share of customers | Fix repeat contacts, long wait times, weak handoffs, and unresolved cases first |
| Low CSAT, low measured DSAT | Feedback design may be under-detecting negative sentiment | Audit survey timing, sampling, response capture, and question framing |
This view changes governance. Teams can move from monthly score reporting to operational diagnosis.
For example, a lender may report acceptable overall CSAT while DSAT spikes in collections, loan status queries, or vernacular support queues. A retailer may see decent satisfaction after order delivery but high dissatisfaction during returns and refund follow-up. In both cases, the average score is less useful than the distribution of negative experience.
That distribution should shape investment decisions.
Why the combined view matters more in AI-led operations
The interaction between CSAT and DSAT becomes even more important when Voice AI is part of the service model. Automation does not improve customer experience by default. It improves experience only when it resolves simple intents faster, routes complex cases correctly, and reduces the conditions that create dissatisfaction in the first place.
That creates a practical management lens for CX leaders in India:
- Use CSAT to identify where AI-assisted journeys are performing well enough to expand
- Use DSAT to identify where automation is creating confusion, escalation, or trust loss
- Track both by intent, language, call outcome, and transfer reason
- Prioritise AI changes where reducing dissatisfaction also lowers cost to serve or improves conversion
This is the non-obvious advantage of treating csat and dsat as one system. One metric tells you where to replicate. The other tells you where to intervene. Voice AI can affect both levers at the same time by shortening resolution time, improving routing accuracy, and reducing dropped or mishandled interactions.
A CX team may call that reporting discipline. A board should see it as profit protection and growth allocation.
Executive interpretation: CSAT indicates where customer experience is strong enough to scale. DSAT identifies where process failure is concentrated enough to erode revenue, raise servicing cost, or weaken retention.
Once both metrics are reviewed together, leadership can ask sharper questions:
- Which journeys create the highest dissatisfaction per 1,000 interactions
- Which segments show acceptable CSAT but poor open-text feedback
- Which negative experience patterns are tied to specific languages, geographies, or call intents
- Which failure points can be reduced through workflow redesign versus Voice AI intervention
That is the shift from scorekeeping to strategy.
How to Measure and Report on CSAT and DSAT
Measurement design decides whether CSAT and DSAT become a management system or a monthly scorecard. If the survey logic is inconsistent, leadership cannot tell whether a score change reflects a real shift in customer experience, a sampling problem, or a reporting artefact.
Start with one method across every high-value interaction. Use the same rating scale, the same timing rule, and the same definition of what counts as satisfied and dissatisfied. That discipline matters more than chasing a perfect questionnaire. A bank, insurer, real estate platform, or education brand operating across languages and channels needs comparability first. Without it, one team reports improvement while another is measuring something different.
For CSAT, use a simple post-interaction question tied to the journey stage. For DSAT, define the bottom end of the same scale as dissatisfaction and track that rate separately. As noted earlier, sample quality also matters. Low response volumes and delayed survey timing can distort both metrics, especially in operations where only highly positive or highly negative customers tend to respond.
A practical survey set could include:
- Post-support call: “How satisfied were you with the help you received today?”
- After a sales demo: “How satisfied were you with the clarity and relevance of the conversation?”
- After a site-visit booking: “How satisfied were you with the ease of scheduling and follow-up?”
- After KYC guidance: “How satisfied were you with the support provided during verification?”
Place one optional open-text question immediately after the score: “What was the main reason for your rating?” The score tells you the size of the issue. The comment identifies the operating cause.
Reporting should then connect customer feedback to business decisions. A board-level view needs more than average scores. It should show where dissatisfaction is concentrated, whether satisfaction is improving after an intervention, and which failure patterns are affecting cost, conversion, or retention. This is the point where CSAT and DSAT work best as a unified system. One highlights experience quality. The other shows where experience failure is expensive.
A useful reporting pack should include:
- Trend lines by journey stage: onboarding, support, collections, renewals, site visits, verification, or claims
- Operational cuts: language, geography, queue, issue type, transfer path, agent cohort, and channel
- Reason-code and text analysis: wait time, repeat contact, unclear explanation, broken handoff, missed callback, or trust concern
- Recovery tracking: whether dissatisfied customers were contacted, the resolution time, and the post-recovery outcome
- Commercial linkage: conversion, repeat purchase, churn risk, escalation rate, and cost to serve by score band
If your team still reviews feedback in spreadsheets, study how modern call centre dashboards that combine CX and operational metrics help leaders trace a DSAT spike back to a queue, script, routing rule, or handoff point quickly. Speed matters. A reporting lag of two weeks can hide a workflow failure that is already hurting renewals or lead conversion.
One reporting rule is often missed. Do not present a single enterprise CSAT and a single enterprise DSAT as the headline for decision-making. Report both by journey, intent, and customer segment where a team can act. Aggregate scores are useful for board visibility, but they rarely show where to change policy, staffing, training, or Voice AI design.
Survey soon after the interaction while recall is fresh. Keep the cadence selective. If every touchpoint triggers a survey, response fatigue rises and sample bias follows. The result is poor measurement, weaker prioritisation, and slower decisions on the issues that matter most.
Industry Benchmarks and Common Strategic Pitfalls
Benchmarking only helps if it changes a decision. A board does not need another average. It needs a reference point that shows whether a score reflects healthy execution, a structural weakness, or a revenue risk.
What good looks like in the Indian market
A sector view is more useful than a national average because customer expectations, service complexity, and contact reasons differ sharply by category.
| Industry | Average CSAT Score (%) | Acceptable DSAT Rate (%) |
|---|---|---|
| BFSI | 75-85 | 0-20 |
| EdTech | 75-85 | 0-20 |
| Real estate | 72-78 | 0-20 |
| Hospitality | 72-78 | 0-20 |
The numbers matter, but the comparison model matters more. A BFSI support queue handling KYC failures should not be judged against a blended enterprise average that also includes routine balance enquiries or low-friction presales calls. The same logic applies in real estate and hospitality, where booking support, lead qualification, payment issues, and post-sale service can produce very different satisfaction patterns.
That is why CSAT and DSAT should sit in the same operating review. CSAT shows where the experience is working well enough to protect retention, conversion, or referral. DSAT shows where friction is concentrated and where cost to serve is likely to rise. Read together, they show whether a process is merely acceptable on average or structurally unstable underneath.
Where leadership teams usually misread the data
The first error is benchmarking the score instead of benchmarking the system that produces the score. A team can sit near the sector average and still destroy value if dissatisfaction is concentrated in high-intent journeys such as loan application support, fee disputes, admissions counselling, or booking modification. In those cases, a stable headline score can mask falling conversion, lower renewal probability, or higher escalation costs.
The second error is reviewing CSAT and DSAT in separate decks owned by different teams. That structure creates slow decisions. A rise in satisfaction among simple queries can hide a worsening dissatisfaction rate in complex cases. Leaders then approve the wrong actions because the average looks stable while the failure points are getting worse. A unified score review fixes that. It forces operations, product, workforce, and CX leaders to assess both positive and negative feedback as part of one service design problem.
The third error is misreading causality. Low scores are often treated as an agent issue because coaching is easier to assign than process redesign. In practice, the root cause is often upstream. Queue design, broken transfers, weak lead qualification, language mismatch, policy friction, or delayed callbacks usually create more dissatisfaction than agent behaviour alone. Voice AI, in this context, alters the economics. It can deflect routine intents, improve triage, shorten wait times, standardise first responses, and route customers to the right resolver earlier. That can raise CSAT and lower DSAT at the same time because both metrics respond to the same operational changes.
A fourth mistake sits in incentives. If managers are rewarded only for high CSAT, they may prioritise interactions that are easy to score well and underinvest in hard journeys that generate complaints, escalations, or churn. If they are judged only on DSAT reduction, they may suppress survey volume or focus on complaint handling without improving the broader experience. Balanced governance treats CSAT and DSAT as paired indicators tied to first-contact resolution, repeat contact, recovery success, and commercial outcomes.
Growth comes from managing the spread between satisfaction and dissatisfaction by journey, not from reporting one enterprise average more often.
The strategic question is simple. Where is the business creating confidence, and where is it creating friction? Boards that answer both questions together allocate budgets better, identify Voice AI use cases faster, and act before dissatisfaction turns into churn, refund pressure, or lost sales.
Actionable Playbooks to Improve CSAT and Reduce DSAT
The fastest gains come when leaders stop asking for general service improvement and start fixing the failure patterns that repeatedly create dissatisfaction.

The DSAT root-cause playbook
Phone interactions in India’s BFSI and EdTech sectors can report DSAT rates up to 35% due to long wait times, which is exactly why broad satisfaction reporting isn’t enough as discussed in this piece on dissatisfaction analysis. When the queue is the failure, coaching the agent won’t solve it.
Use a root-cause process that forces specificity:
- Tag every negative score by issue category. Use labels such as wait time, repeat contact, compliance friction, wrong transfer, incomplete answer, language mismatch, or missed follow-up.
- Separate controllable from systemic causes. Agent behaviour and queue design should never sit in the same bucket.
- Review the top category weekly. Don’t wait for the monthly governance pack.
- Assign one owner per failure theme. Product, operations, training, and workforce teams should each own the categories they control.
For operating leaders building stronger QA and escalation design, this guide to call centre management best practices is useful because it connects frontline discipline with broader service outcomes.
The service recovery playbook
Once a customer gives a poor rating, speed matters. A recovery model should be automatic, not discretionary.
- Flag priority responses: Trigger a senior callback or personalised follow-up for the most severe dissatisfaction signals.
- Respond with context: The recovery owner should see the call reason, queue, agent, and comment before contacting the customer.
- Close the loop: Mark whether the issue was acknowledged, fixed, or transferred.
Teams that already collect customer feedback but struggle to operationalise it usually benefit from a more structured voice of customer approach. The board should expect evidence that dissatisfied respondents are not just counted, but actively managed.
A dissatisfied customer who receives a thoughtful, timely recovery often teaches you more than ten satisfied ones.
This is also where governance needs nuance. Don’t ask every team to chase every negative response. Focus recovery on high-value journeys, repeatable process failures, and moments where trust matters most, such as identity verification, booking, onboarding, and payment support.
A short briefing can help teams visualise what a good recovery workflow looks like in practice:
The FCR and queue-friction playbook
High dissatisfaction often clusters around unresolved first contacts. That’s why leadership should read csat and dsat alongside first-contact resolution, repeat contact, and wait-related tags.
A disciplined intervention looks like this:
| Failure pattern | Likely cause | Strategic move |
|---|---|---|
| High DSAT on first calls | Queue delays or weak triage | Redesign routing and callback options |
| Good CSAT for solved cases, weak overall score | Too many repeat contacts | Improve knowledge base and ownership rules |
| Negative scores in multilingual flows | Script rigidity or language mismatch | Localise prompts and escalation logic |
| Pain in compliance-heavy journeys | Overly linear verification process | Break workflow into simpler guided steps |
The leadership lesson is simple. Don’t try to “raise satisfaction” in the abstract. Remove the specific friction that repeatedly creates dissatisfaction, then measure whether both scores move in the expected direction.
Amplifying Results with DialNexa Voice AI
Response speed shapes outcomes fast. In high-intent journeys such as property enquiries, loan support, admissions counselling, and payment assistance, a missed first interaction often becomes both a revenue leak and a dissatisfaction trigger.

Voice AI matters because it can change CSAT and DSAT through the same operating moves. Immediate answer rates improve the customer’s first impression. Better intent capture reduces routing errors. Structured follow-up lowers drop-off between stages. Boards should view this as one system, not two reports.
As noted earlier, weak qualification and inconsistent early-stage handling are major sources of dissatisfaction in real estate. The larger strategic issue is that the same failure also suppresses conversion. If prospects cannot connect quickly, repeat information across calls, or wait for manual callbacks, the business loses both trust and pipeline quality.
A platform such as AI agents for customer service becomes useful when it is configured against those specific points of failure. The Voice AI layer can answer inbound calls instantly, qualify intent in a consistent format, route serious buyers to the right team, and trigger follow-up without relying on manual discipline. That improves customer experience and sales efficiency at the same time.
The same pattern appears beyond real estate.
In EdTech, counselling quality often drops during admission peaks, especially across language preferences and time-sensitive callback windows. In BFSI, dissatisfaction rises when verification flows become repetitive, context is lost between channels, or customers are transferred without a clear resolution path. In both sectors, Voice AI improves performance when it captures context upfront, confirms the next step clearly, and sends the human agent into the conversation with usable information instead of a blank screen.
A useful reference point is this overview of conversational AI for customer support. The board-level question is not whether AI answers calls. The fundamental question is whether it removes known friction in high-value journeys and creates cleaner operational data for intervention.
That is the compounding advantage. Higher CSAT comes from faster, clearer, more consistent interactions. Lower DSAT comes from fewer missed calls, fewer repeat explanations, and fewer broken handoffs. The commercial upside follows naturally through stronger conversion, better agent productivity, and tighter control over customer-facing processes.
Frequently Asked Questions for CX Leaders
Should we optimise for CSAT or DSAT first
Start with the sharper risk. If the organisation has visible friction, recurring complaints, or workflow failures, reduce DSAT first. If the service is stable but inconsistent, improve CSAT by replicating successful journeys. In practice, most boards should watch both together and prioritise the area that is most closely tied to revenue, trust, or compliance exposure.
How many responses do we need before acting
For dissatisfaction analysis, treat 30 to 50 responses as basic validity and 100+ responses as a stronger base for high-volume operations, especially when response rates sit in the 10 to 15% range, as noted earlier from Fullview. But don’t wait for perfect volume if the same complaint appears repeatedly in comments or in one workflow. Operational evidence matters alongside survey maths.
Can Voice AI improve both scores at once
Yes, if it removes real friction rather than deflecting calls. The biggest improvements usually come when AI handles immediate connection, qualification, repeatable explanations, reminders, and routing context well. It can also make scores worse if the flow lacks sentiment awareness, escalation logic, or multilingual nuance. The lesson for CX leaders is to deploy automation against known failure points, not as a blanket cost-cutting layer.
What should go to the board each month
Keep the board pack tight and decision-oriented. Include:
- Trend movement: How CSAT and DSAT changed across the most valuable journeys.
- Top failure themes: The recurring reasons for poor scores, based on tagged comments.
- Action status: Which fixes were deployed and whether the scores changed after rollout.
- Segment exposure: Where dissatisfaction is concentrated by channel, language, queue, or customer type.
- Recovery performance: Whether dissatisfied customers received timely follow-up.
Good governance doesn’t ask, “What is our score?” It asks, “What did we learn, what did we fix, and what changed after the fix?”
A mature programme makes one final shift. It stops treating customer feedback as a service KPI owned by one function. It turns csat and dsat into shared operating signals across CX, operations, product, sales, and technology. That’s where the commercial value shows up.
If your team wants to turn customer feedback into a tighter operating system, DialNexa Labs Private Limited offers Voice AI workflows for qualification, support, presales, and follow-up that can fit sectors such as BFSI, EdTech, real estate, hospitality, e-commerce, and SaaS. The practical next step isn’t to chase a bigger dashboard. It’s to identify the customer journeys where dissatisfaction is concentrated, instrument those moments properly, and deploy automation only where it can improve both experience quality and business outcomes.
[…] Second, it hurts CX at scale. Frustration in banking voice support doesn’t stay inside the contact centre. It affects app ratings, branch complaints, retention, and service trust. If your executive team reviews only average call volumes and misses the deeper relationship between failed automation and dissatisfaction, you’re managing the wrong dashboard. A stronger way to think about this is through customer sentiment metrics such as CSAT and DSAT in service operations. […]