
Voice AI Agents for Developers: A CXO’s Guide for 2026
Voice AI projects fail in production for boring reasons that never appear in launch demos. Latency spikes across regions. Speech pipelines break under call concurrency. CRM writes timeout mid-conversation. Compliance logs are incomplete when legal asks for an audit trail. Choosing a model matters, but runtime design, integration discipline, and evaluation coverage decide whether the system produces revenue or support debt.
That is the gap this guide addresses. Vendors sell easy deployment. Development teams inherit packet loss, barge-in handling, telephony edge cases, multilingual routing, noisy audio, and the requirement to connect every call outcome back to systems that finance, operations, and customer teams already trust. At small scale, those problems are annoying. At thousands of calls per day, they determine containment rate, average handle time, conversion, and whether the programme clears executive ROI thresholds.
Directors should treat voice AI as an operating system for customer interactions, not a feature experiment. Engineering leads should measure it the same way they would any revenue-affecting platform: uptime, median response latency, failure recovery, observability, integration accuracy, and cost per completed task. Teams that want a concrete benchmark for business-ready calling workflows can compare against DialNexa's AI call bot reference implementation.
The sections that follow focus on the work many tutorials skip: architecture choices, system integration, test design, and production operations that hold up after the pilot.
Table of Contents
- The Strategic Case for Building Production-Grade Voice AI
- Architecting Voice Agents for Performance and Scale
- A Developer's Workflow for Building and Training Agents
- Integrating Voice AI into Your Business Systems
- Framework for Testing and Evaluating Agent Performance
- Deploying, Monitoring, and Optimising at Scale
- Conclusion: From Developer Project to Strategic Asset
The Strategic Case for Building Production-Grade Voice AI
Production-grade voice AI is an operating decision before it becomes a model decision.
The board cares about cost per resolved interaction, coverage outside business hours, conversion speed, and compliance exposure. Engineering cares about latency budgets, failure handling, system integration, and whether the agent can complete a task without creating downstream cleanup work. Those priorities meet in the same place. A voice agent only creates value when it performs reliably inside the systems that already run the business.
That is the gap many teams underestimate. A polished conversational layer is only one part of the job. The harder work sits underneath it: telephony events, state management, CRM writes, identity checks, retrieval quality, audit trails, and escalation paths. Teams evaluating an AI call bot for business workflows usually find that the return depends less on how human the voice sounds and more on whether the agent finishes the process correctly.
Why the board should care
For executive teams, voice AI changes unit economics.
A well-built agent can absorb repetitive call volume, keep outbound and support queues active after hours, and standardise execution across locations and teams. That shifts labour from low-complexity calls to revenue-generating or exception-handling work. It also gives leadership tighter control over how regulated scripts, qualification rules, and service processes are followed.
The impact is strongest in functions where speed, consistency, and coverage affect revenue or service levels.
- Sales operations: Faster lead response reduces the gap between intent and contact, which protects conversion.
- Customer support: High-volume first-line requests can be handled without matching headcount to every spike in demand.
- Regulated workflows: Approved responses, disclosures, and verification steps can be enforced more consistently.
- Distributed operations: One platform can support multiple regions, business units, and service windows if the underlying design is sound.
Voice becomes strategically useful when it is treated as a service layer for repeatable customer-facing work, not just another channel.
Why engineering should care
Engineering inherits the consequences of every shortcut.
If the agent speaks clearly but fails to sync the booking, support teams fix records by hand. If it retrieves the wrong account state, trust drops fast. If it cannot recover from interruptions, retries, or partial answers, resolution rates fall and transfer rates rise. Those are not abstract technical flaws. They show up as longer handle times, lower conversion, more escalations, and avoidable operational cost.
Senior teams treat voice as part of the operating stack. That means designing for orchestration across speech recognition, reasoning, retrieval, business rules, compliance controls, and transactional APIs. It also means defining success in business terms. Containment, successful task completion, clean CRM updates, and safe escalation usually matter more than whether a demo sounded impressive.
This is why production voice AI belongs in roadmap and budget discussions early. The investment is justified when the architecture reduces manual workload, protects service quality, and scales without multiplying support overhead.
Architecting Voice Agents for Performance and Scale
The architecture decides whether your agent feels sharp, trustworthy, and economical, or slow, brittle, and expensive. The commercial benchmarks are already strong enough to justify careful engineering. Production systems can respond in about 800 milliseconds, achieve 92% first-level query resolution, deliver 240–380% ROI within six months, and reduce customer-support operating costs by 20–30%, according to these voice agent performance benchmarks. The same source notes that one telecom firm reduced call handling time by 35% after implementation.
Teams building on retrieval-heavy workflows often benefit from patterns similar to those used in a knowledge-based agent in AI, where answer quality depends on precise grounding rather than generic model fluency.
Where strong architectures differ from demos
A demo pipeline can tolerate pauses, manual resets, and narrow prompts. Production traffic can’t. The actual architecture has to survive half-spoken answers, retries from upstream systems, stale CRM state, and customers changing intent mid-call.
The most useful design principle is simple: optimise the whole turn, not a single model. A fast ASR layer with poor recognition hurts downstream reasoning. A powerful reasoning layer with slow tool execution still feels broken to the caller. A natural TTS layer can’t save a workflow that retrieves the wrong account record.
The four components that decide outcomes
| Component | What it must do well | Common trade-off | Business impact |
|---|---|---|---|
| ASR | Capture what the caller actually said | Speed versus accent robustness | Errors here distort every later step |
| NLU and reasoning | Identify intent and choose the right next action | Smaller model cost versus deeper reasoning | Determines containment and compliance |
| Dialogue management | Manage turns, interruptions, and state | Simplicity versus resilience | Directly affects resolution quality |
| TTS | Respond clearly and naturally | Voice quality versus latency | Shapes trust and caller comfort |
A reliable stack usually separates these concerns instead of asking one model to do everything.
- ASR should be tuned for domain and region. Banking terminology, educational programmes, and property inventory each have their own vocabulary. Generic transcription is often not enough.
- Reasoning should be constrained by policy. In regulated environments, retrieval and instruction hierarchy matter more than model creativity.
- Dialogue logic should own the state. Don’t let conversation memory float loosely across turns when actions depend on verified details.
- TTS should be selected for response rhythm. Natural pauses and interruption handling matter as much as voice tone.
Practical rule: If you can’t explain what happens when a user interrupts during tool execution, the system isn’t ready for production.
Latency, accuracy, and concurrency have to be designed together
Leaders often ask which metric matters most. In practice, the answer is sequencing. First, keep the turn fast enough to preserve flow. Next, make sure the answer is correct. Then prove the stack can do it repeatedly under concurrency.
Many “easy deployment” claims collapse under closer scrutiny. The hard engineering work sits in stream handling, session state, retries, observability, and fallback logic. When those parts are solid, voice stops being a novelty and starts functioning like a dependable service.
A Developer's Workflow for Building and Training Agents
The training workflow for voice ai agents for developers should begin with a blunt assumption: your first model isn’t the product. Your data, evaluation process, and correction loop are the product. That’s especially true in India, where multilingual speech, code-switching, and noisy environments punish generic pipelines.

For Indian deployments, successful builds require 10,000+ hours of regional call data and ASR fine-tuning to reach WER below 5% for Hinglish, according to this voice agent report focused on deployment quality. The same report notes that when local noise profiles are ignored and SNR falls below 16 dB, task success can drop from 90% to 42%.
Start with data that matches the market
The fastest way to derail a build is to train on clean, generic audio and deploy into messy, regional call traffic. Accent diversity, agent scripts, domain phrases, and background conditions all need to be represented before any optimisation claim is credible.
A practical data plan usually includes:
- Collect domain-specific conversations from the exact workflow you want to automate, such as admissions counselling, collections reminders, support triage, or property qualification.
- Annotate for intent and task completion, not just transcript quality. Resolution depends on whether the agent reached the right operational outcome.
- Segment by acoustic conditions so the team can isolate poor performance caused by call quality rather than model logic.
- Tag language mixing and vocabulary drift such as Hindi-English switching, local pronunciations, or brand-specific product names.
Persona work belongs here too. The agent voice should match the brand and the use case. A collections reminder, a student counsellor, and a support specialist should not sound interchangeable.
Train for the conversation you will actually get
Most failures in early pilots come from unrealistic dialogue assumptions. Users interrupt. They answer indirectly. They ask for confirmation in fragments. They return to a previous topic after a side question. Training has to reflect that.
Good teams pressure-test three layers at once:
- Recognition quality: Can ASR preserve meaning under noise and code-switching?
- Intent stability: Does the system hold the right intent after several turns?
- Action discipline: Does the agent follow process rules instead of improvising?
A workflow mindset helps here. Teams that already use structured delivery practices from a modern software development guide usually perform better because they version prompts, track regressions, and test changes systematically instead of tweaking live behaviour ad hoc.
The build fails long before launch if prompt changes, data revisions, and evaluation runs aren’t managed like software.
Operationalise the workflow
A practical operating rhythm looks like this:
- Week one focus: establish baseline transcription and intent quality on real calls.
- Next stage: tune prompts, retrieval, and turn handling using flagged failure cases.
- Before broader rollout: test with shadow traffic and compare completed tasks against human-handled baselines.
- After launch: feed failed conversations back into annotation and retraining queues.
What works is disciplined iteration. What doesn’t work is assuming a strong base model will absorb every edge case. In voice systems, weak data design surfaces quickly and publicly.
Integrating Voice AI into Your Business Systems
A standalone voice bot can answer questions. An integrated agent can move work forward. That’s the line executives should care about, because value appears when the system doesn’t just talk, but reads account context, checks eligibility, triggers workflows, logs outcomes, and hands off cleanly.
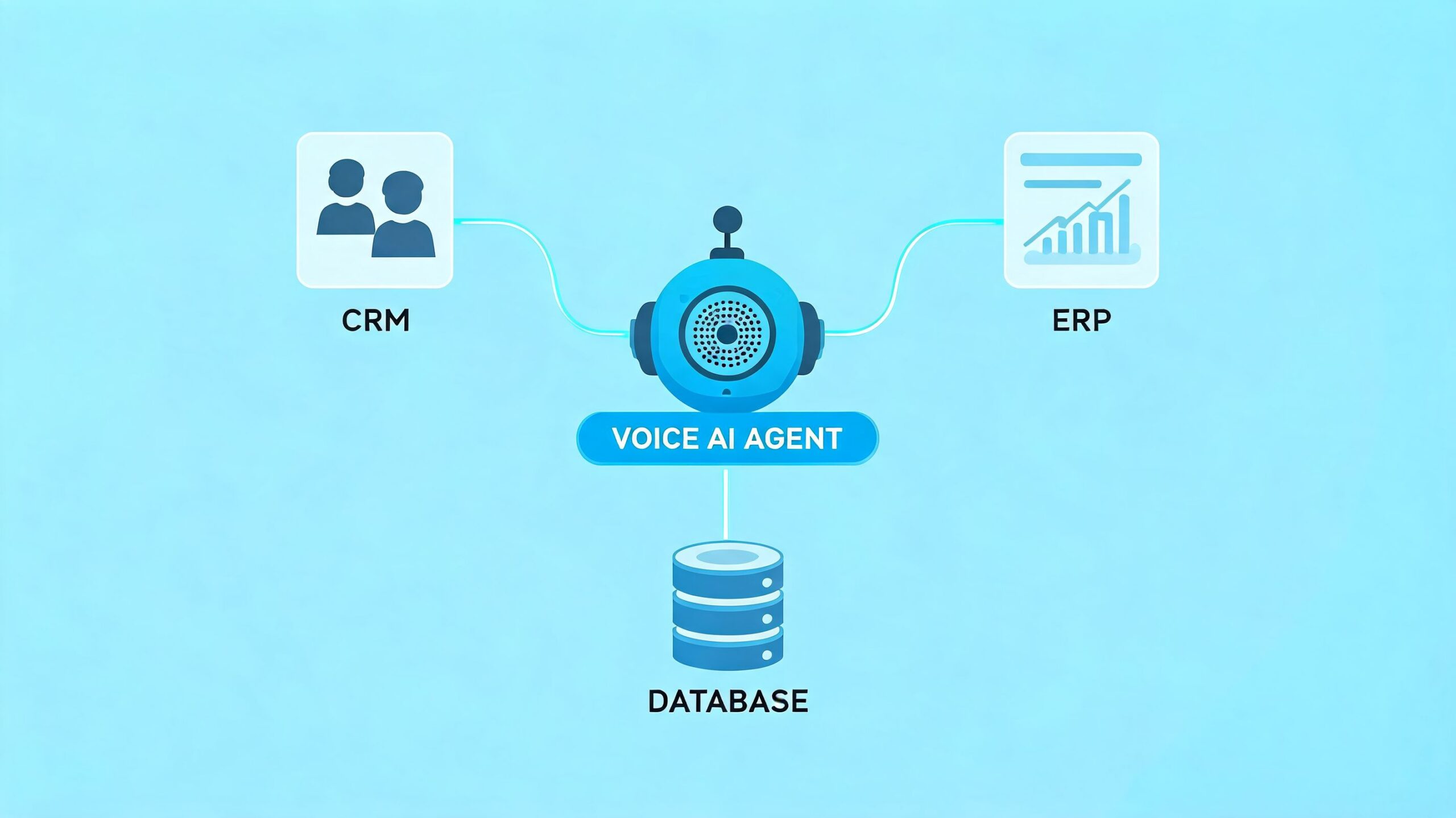
The difference between a talking bot and a useful agent
An agent becomes operationally useful when it can:
- Read live business context: CRM records, order status, programme details, or inventory availability.
- Execute controlled actions: create a lead note, update status, book a slot, or trigger a callback.
- Follow enterprise rules: verify required details before acting.
- Escalate with context: pass the conversation summary and collected data to a human team member.
Consider an EdTech example. A prospect answers a qualification call. The agent identifies programme interest, checks the relevant course information from an internal knowledge source, looks up available counsellor slots, and books the meeting in one flow. That single conversation replaces multiple manual steps.
A practical integration pattern
The cleanest pattern is usually event-driven orchestration around a narrow action layer.
- Voice session layer captures speech, turn state, and user identity hints.
- Decision layer determines whether to answer, retrieve, ask, verify, or act.
- Tool layer calls CRM, scheduling, payments, ticketing, or ERP APIs.
- Audit layer writes summaries, statuses, and failure logs.
Business systems rarely fail gracefully. A scheduling endpoint might timeout. A CRM record may be duplicated. A product catalogue may be outdated. The agent needs deterministic action rules and fallback copy for each of those conditions.
Teams launching new products or outbound workflows often need custom connectors as part of that layer. In those cases, it’s useful to review options that integrate with the Saaspa launch platform so the voice workflow can trigger operational actions without manual intervention.
A short implementation walkthrough helps visualise the pattern:
Design the integration for failure handling
The integration should never assume downstream systems are always available. Build specific behaviours for partial failure.
| Failure case | Better handling choice | Poor handling choice |
|---|---|---|
| CRM lookup fails | Ask permission to continue with limited context and queue a follow-up sync | Pretend the record exists |
| Calendar API times out | Offer to confirm later and log priority callback | Repeat the same booking attempt indefinitely |
| Inventory is stale | State that availability needs confirmation | Promise an unavailable option |
| Compliance condition is unmet | stop the transaction and escalate | Let the model guess |
The technical pattern is straightforward. The discipline is harder. Every action should have preconditions, failure branches, and logging. That’s what turns speech into a governed workflow instead of a conversational facade.
Framework for Testing and Evaluating Agent Performance
The fastest way to lose executive support is to report attractive speech metrics while the business outcome stays flat. A voice agent can sound fluent and still fail operationally. That’s why evaluation has to connect technical quality to resolution, transfer behaviour, and task completion.
A dependable early framework should target intent accuracy above 95% and transfer rate below 20% in the first 30 days, then evolve toward FCR above 75%, according to Twilio’s guidance on evaluating voice AI agents. The same source notes that top performers such as DialNexa achieve 97% lead qualification accuracy, matching human judgement. Teams building analytics around those outcomes often benefit from studying contact centre voice AI analytics production pipelines and metrics.
Measure business outcomes, not just speech quality
Start with a layered scorecard. Don’t treat all metrics as equal.
- Foundational metrics: transcription quality, intent accuracy, latency, tool success rate.
- Operational metrics: transfer rate, first call resolution, containment, repeat contact drivers.
- Executive metrics: qualified leads, booked appointments, support deflection, cost per completed task.
A support leader cares whether the agent resolved the issue. A sales VP cares whether the lead was qualified and progressed. A CTO cares whether the stack remained stable while doing both.
If a dashboard can’t tell a director whether the agent reduced workload or increased pipeline movement, it’s the wrong dashboard.
A scorecard leaders can use
Here’s a practical way to organise review meetings:
| Review lens | Key question | Signal to watch |
|---|---|---|
| Customer experience | Did callers complete their task without friction? | Resolution, transfer reasons, repeated prompts |
| Operational efficiency | Did the agent remove manual work? | FCR, containment, escalation quality |
| Commercial impact | Did calls progress revenue or retention goals? | Qualification accuracy, bookings, follow-up completion |
| Technical reliability | Did the platform perform consistently? | Latency trends, API failures, state loss |
This structure prevents teams from hiding behind a single number. A high intent score with weak completion still means the system needs work.
How to run safer evaluations
The safest pattern is incremental exposure.
- Shadow deployments: run the new version against live traffic without letting it own the outcome.
- A/B prompt comparisons: compare completion quality, not just style preferences.
- Failure clustering: group bad calls by cause, such as ASR confusion, retrieval error, tool timeout, or policy drift.
- Human review loops: audit a sample of successful calls too, not just failures.
Plainly put, the evaluation framework should tell you why performance moved, not just whether it moved. That distinction saves weeks of blind tuning.
Deploying, Monitoring, and Optimising at Scale
Deployment often suggests readiness to developers. In voice systems, however, deployment reveals reality. The first week in production exposes latency spikes, handoff problems, stale retrieval, and integration branches that never appeared in testing.
The operational stance should be simple: treat launch as the start of an optimisation cycle. Production voice depends on continuous measurement, because caller behaviour changes, backend systems drift, and speech conditions vary throughout the day.
What operations teams should monitor live
The right live dashboard is narrow and actionable. It should help an engineering lead decide whether to roll forward, revert, route differently, or investigate upstream systems.
Monitor these categories in real time:
- Conversation health: latency distribution, interruption handling failures, silent turns, dropped sessions.
- Decision quality: fallback frequency, repeated clarification loops, low-confidence intents.
- Integration health: CRM write failures, retrieval misses, booking errors, authentication failures.
- Business outcomes: completion status by use case, escalation reasons, booked versus abandoned workflows.
Don’t bury operators in vanity charts. A small set of alertable indicators is better than a large observability wall nobody uses.
Optimisation is a weekly discipline
The best improvement loops combine quantitative telemetry with reviewed call samples. Look for patterns rather than isolated incidents. If transfer reasons cluster around one product line, the issue may be retrieval coverage. If callers repeat themselves after a greeting, the issue may be turn timing or opening prompt design. If tasks fail after verification, the problem may sit in system integration rather than language understanding.
A mature programme usually does three things every week:
- Review failed and borderline conversations for root cause, not blame.
- Promote fixes selectively through canary or limited routing rather than broad replacement.
- Update prompts, retrieval sources, and action rules together so one layer doesn’t regress another.
Strong voice operations teams don’t ask whether the model is good. They ask which part of the call path is creating friction and how quickly they can remove it.
Scaling to large daily volumes requires that discipline. Without it, every incremental rollout increases complexity faster than value. With it, the system improves as traffic grows.
Conclusion: From Developer Project to Strategic Asset
Voice AI earns its place when it stops being a showcase feature and starts carrying measurable business work. That shift doesn’t happen because a model sounds human. It happens because the system is architected for low-latency interaction, trained on the right data, connected to the right business tools, and evaluated against outcomes leaders care about.
For developers, this is one of the clearest opportunities to build software that directly changes operational performance. For directors and CXOs, it’s a path to more consistent customer engagement, faster qualification, cleaner support handling, and tighter control over repetitive workflows.
The strongest teams approach voice as a product and an operating capability at the same time. They design for failure, instrument everything that matters, and keep improving after launch. That’s what turns voice ai agents for developers from an experimental initiative into a strategic asset.
If your team wants to move from pilot conversations to production-grade calling workflows, DialNexa Labs Private Limited offers human-like Voice AI agents for qualification, customer support, recruitment, and presales across industries including EdTech, BFSI, real estate, hospitality, e-commerce, and software. The platform is designed for teams that need scalable deployment, industry-specific workflows, API-driven integration, and measurable business outcomes without turning every launch into a heavy engineering project.
[…] teams exploring telephony and interaction-layer decisions, DialNexa's overview of voice AI agents for developers is useful because it frames the stack around deployment and operational fit rather than just model […]