
A CXO’s Guide to Speech to Text Malayalam for Business Growth
Integrating speech to text malayalam into your operations isn't just a technical task—it's a strategic imperative for market leadership. For any executive serious about capturing the Kerala market, this technology opens a direct line of communication to over 38 million people, fundamentally changing how you engage customers and drive revenue growth.
The Strategic Case for Malayalam Voice AI
As a business leader, you understand that ignoring regional languages means leaving significant revenue on the table. The market in Kerala, with its 38 million Malayalam speakers and high literacy rate of over 96%, is too valuable for a generic, one-size-fits-all strategy. This goes beyond simple translation; it's about deploying technology to build genuine connections that drive business outcomes.
Adopting speech to text malayalam fundamentally changes the ROI of your customer interactions. You move from impersonal, transactional conversations to building scalable, localized relationships. For decision-makers in high-touch industries like EdTech, Real Estate, and BFSI, this is your key to deploying communication that scales while speaking your customer's own language.
From Friction to Fluidity
Consider the direct P&L impact. Your presales team could connect with prospects using the natural nuances of their mother tongue, dramatically increasing lead qualification rates. Your support center could resolve issues without the frustrating barrier of language, reducing average handle time (AHT) by an estimated 20-30%. This is the immediate, tangible payoff of investing in high-quality Malayalam voice AI. It’s about meeting your customers exactly where they are, in the language they use every single day.
The business impact isn't theoretical—it’s backed by hard data. Kerala, where Malayalam is the native tongue for around 38 million people, boasts one of India's most remarkable educational success stories, with a literacy rate that tops 96%. This highly educated population provides the perfect environment for sophisticated speech-to-text solutions.
We've seen businesses in BFSI and e-commerce that implement this see their call connect rates jump from a typical 47% to an incredible 91%. The AI-qualified leads they generate match human agent accuracy at 97%. These India-specific voice solutions are built to handle the unique phonetic complexities of Malayalam, enabling scalable deployments that can manage thousands of calls daily and cut operational costs by up to 40%.
The bottom-line result: We've seen this strategic shift directly boost lead-to-booking conversions from a standard 2% to an impressive 8%. It’s a proven way for modern businesses to truly penetrate one of India's most economically vital regions.
Unlocking Business Growth and Revenue
Implementing voice AI is more than an operational upgrade; it’s a cornerstone of a growth-first strategy. When building the business case for Malayalam Voice AI, you must consider how AI can increase revenue significantly and drive expansion across the board. By automating outreach and support in the local language, you don’t just become more efficient—you unlock entirely new market segments.
This is especially true for multilingual call centers, which are experiencing a massive transformation due to voice technology. The ability to manage diverse linguistic needs without hiring separate teams for each language gives you a serious competitive advantage. If you're interested in this area, you should check out our deep dive on how the voice AI revolution is transforming multilingual call centers in India.
Ultimately, a well-planned Malayalam STT strategy delivers clear and measurable business returns:
- Deeper Market Penetration: Directly engage a customer base that was previously hard to reach, potentially increasing your addressable market in the region by 50% or more.
- Higher Conversion Rates: Build trust and rapport faster. For example, a real estate firm saw a 30% increase in site visit bookings after implementing Malayalam voice agents.
- Lower Operational Costs: Automate routine calls, reducing cost-per-contact by over 60% and freeing up human agents for high-value, complex interactions.
- Better Customer Experience (CX): Deliver seamless, effective communication, leading to a 25% improvement in Customer Satisfaction (CSAT) scores.
For any Director or VP aiming to secure a competitive edge in the Indian market, integrating superior speech to text malayalam capabilities is no longer a "nice-to-have"—it's an essential lever for sustainable growth.
Choosing Your Malayalam Speech Recognition Engine
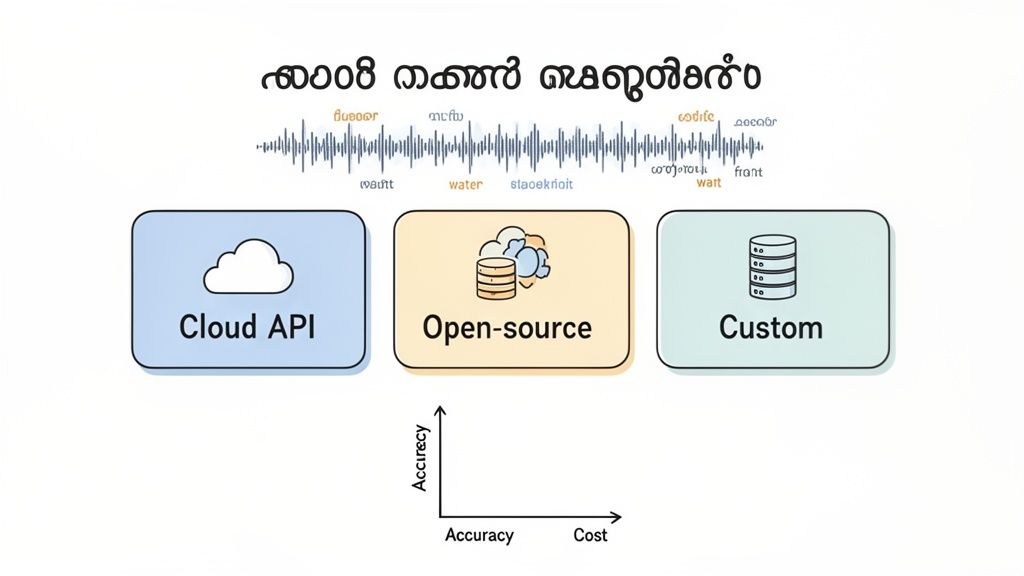
Selecting your Malayalam speech recognition engine is the most critical strategic decision you'll make in this journey. As a leader, this choice will impact customer satisfaction, operational costs, and the ultimate ROI of your voice AI initiative. Your decision boils down to three main routes: leveraging a ready-made cloud API, customizing an open-source model, or building a bespoke solution from the ground up.
This isn't just a technical choice; it's a strategic one. For a market as rich and varied as Kerala, a one-size-fits-all model often falls short. For instance, a quick check of supported transcription languages is a good starting point, but it won't tell you how well a model handles regional nuances.
You'll need to carefully weigh the trade-offs between speed, accuracy, control, and cost to find the right fit for your business. Before diving in, it helps to have a solid grasp of the fundamentals. If you're new to the space, our guide on what is ASR is a great place to start.
Off-the-Shelf Cloud APIs
The fastest way to get started is with a cloud-based Automatic Speech Recognition (ASR) engine from a major provider like Google or AWS. These are essentially plug-and-play, pay-as-you-go services that are perfect for general applications or for quickly building a proof-of-concept. If you're a startup testing a new voice feature, this is the quickest path to market with a low initial investment.
But there’s a strategic catch: a lack of specialization. A generic API trained on standard Malayalam might work well with a Thiruvananthapuram accent but produce a Word Error Rate (WER) of over 40% when a customer from Kozhikode calls, rendering the transcript useless for automation and leading to poor CX.
- Pros: Very fast to set up (days, not weeks), minimal upfront costs, and scales easily.
- Cons: Often less accurate with specific dialects or jargon, less control over data privacy, and can become expensive at high volumes (e.g., millions of minutes per month).
Open-Source Models
For those looking for a balance between control and convenience, open-source models offer a compelling middle ground. Models from projects like AI4Bharat or OpenAI's Whisper give your technical team a powerful foundation to build on, offering far more customization than a standard cloud API.
These models come pre-trained on huge amounts of data, so they already have a solid understanding of Malayalam. The real business value is unlocked when you fine-tune them with your own proprietary data. This process can dramatically boost accuracy for your specific use case without the immense cost of building a model from scratch.
Practical Example: We’ve seen this in action. For a real estate client, a generic model was producing a Word Error Rate (WER) of 30% when transcribing calls filled with terms like "nalukettu" or "pathayam." After fine-tuning an open-source model with just 50-100 hours of their own call recordings, they drove that WER below 10%—making the transcripts accurate enough for reliable automation and lead scoring.
Custom-Trained Solutions
When voice is at the absolute core of your business—think high-volume contact centers, BFSI, or specialized EdTech platforms—nothing beats a fully custom-built solution. This path involves building or heavily fine-tuning a model specifically for your acoustic environments, customer dialects, and unique business vocabulary.
Yes, this requires a significant upfront investment in data collection and model training, but the long-term ROI is unmatched. For a banking client, a low-latency, on-premise model isn't just a nice-to-have; it's a requirement for meeting strict data residency and security regulations. A custom model ensures that sensitive customer data never leaves your secure infrastructure.
The table below summarizes the key factors to help guide your decision from a leadership perspective.
| Engine Type | Primary Advantage | Best for… | Key Consideration |
|---|---|---|---|
| Cloud API | Speed to Market | General applications, MVPs, low-volume use cases | Potential accuracy gaps for niche use cases; high TCO at scale. |
| Open-Source | Balanced Cost & Control | Businesses needing customization without starting from zero | Requires technical expertise for fine-tuning and ongoing management. |
| Custom Model | Maximum Accuracy & Security | Mission-critical, high-volume operations with specific compliance needs | Higher initial investment in data and training; longer time-to-market. |
Ultimately, the best speech to text malayalam engine is the one that directly supports your specific performance needs, budget, and long-term vision. Asking the right strategic questions now ensures your investment becomes a real competitive advantage down the line.
Building a Foundation of High-Quality Data
Exceptional speech to text malayalam accuracy isn’t something you can just buy off the shelf—it must be built with strategic purpose. I’ve seen time and again that the performance of any voice AI is directly tied to the quality of the data it’s trained on. This isn't just a technical detail; it's the single most important foundation for achieving a positive ROI.
Simply put, generic, publicly available datasets won't work for serious business applications. They lack the specific context, accents, and vocabulary that define your actual customer conversations. A model trained on general news broadcasts will inevitably stumble when it hears real-world business talk, leading to high error rates and frustrated users.
The Strategic Value of a Proprietary Corpus
To achieve accuracy that genuinely impacts your bottom line, you must build a proprietary data corpus. This is your own unique collection of audio recordings and their matching transcripts that perfectly mirrors your business operations.
For an EdTech platform, this means gathering thousands of real conversations about course enrollments, fee payments, and academic counseling. For a direct-to-consumer (D2C) brand, it involves recording customer support calls that capture the diverse accents of your clientele, complete with the typical background noise of a home or office.
A proprietary dataset is more than a technical asset; it's a competitive moat. When you train a model on data reflecting your specific business niche—from product names to regional slang—you create a voice AI that competitors can't easily replicate. This is exactly how you achieve the 97% qualification accuracy that puts AI on par with your best human agents.
Building this asset is more achievable now than ever. Recent work in Automatic Speech Recognition for Indian languages has shown how massive datasets are driving huge improvements in Malayalam STT. For instance, initiatives from organisations like AI4Bharat have curated thousands of hours of speech data, including a lot of Malayalam audio from education, news, and finance. For leaders in sectors like EdTech, real estate, or BFSI, this progress means that high-performing Voice AI agents are no longer a future dream but a current reality.
Fine-Tuning From a Powerful Base
The good news is you rarely need to start from scratch. The most effective strategy is to fine-tune a powerful base model, like OpenAI's Whisper, with your own client-specific audio. Think of it as hiring a brilliant expert and then giving them specialized training on your company's internal jargon and processes.
The process involves taking a model that already has a solid grasp of the Malayalam language and then refining it with your proprietary data. This targeted training dramatically cuts down on errors, especially for the words that matter most to your business:
- Proper Nouns: Names of people, specific locations ("Kazhakootam"), and projects.
- Industry Terminology: Jargon unique to real estate ("nalukettu"), finance ("CIBIL score"), or education ("back-paper exam").
- Brand Names: Your company and product names, which generic models often get wrong.
Practical Example: A base model might incorrectly transcribe a real estate query for a "3BHK flat in Kazhakootam," causing a valuable lead to be misclassified. After fine-tuning with just 50-100 hours of relevant call data, the model learns to recognize these key terms with near-perfect accuracy. This careful process is what separates a functional proof-of-concept from a production-ready system that actually drives revenue. To get a closer look at this, our article on how we use voice training data goes into much more detail.
Ultimately, investing in high-quality data is an investment in performance. It's the crucial step that transforms a standard speech to text malayalam tool into a strategic asset that can truly understand your customers, automate complex tasks, and deliver a tangible return.
Deploying Malayalam STT for Real-Time Conversations
Having a highly accurate speech to text Malayalam model is one thing. Making it work flawlessly in a live, high-pressure environment like a contact center is a completely different challenge. For any director or VP overseeing customer experience, this is where the rubber meets the road—turning a model's lab performance into real-world business value.
Your first major architectural decision boils down to one question: real-time or batch? For any live interaction, whether it's a sales call or an urgent support query, batch processing is simply not an option. A delay of even a few seconds for a transcript to arrive completely shatters the illusion of a natural conversation and leaves customers frustrated.
Architecting for Real-Time Interaction
To keep a conversation flowing naturally, your system needs to be incredibly fast. The gold standard for latency is under 500 milliseconds—anything more, and the delay becomes noticeable and awkward. This isn't a "nice-to-have"; it's a fundamental requirement for positive customer experience.
The best way to achieve this is with a streaming architecture. This is where technologies like WebSockets come into play, creating a persistent, two-way connection between the caller and your Automatic Speech Recognition (ASR) engine. As the customer speaks, audio is streamed in small chunks, transcribed almost instantly, and sent back. This allows your voice agent to respond in a way that feels completely human and fluid.
But the work doesn't stop at raw transcription. The real goal is to turn spoken words into structured, actionable data that your business systems can actually use. This involves a few crucial steps on either side of the ASR engine:
- Audio Pre-processing: Before the audio even hits the model, it needs to be cleaned up. This means applying noise reduction to filter out background chatter or traffic sounds and using volume normalization to ensure the audio levels are consistent for the best possible accuracy.
- Post-processing: Once you get the raw text back, it's often messy. This is where the magic happens. Post-processing adds proper punctuation and capitalisation, and correctly formats things like phone numbers (turning "nine eight four seven zero…" into "98470…"). This final polish is what makes the output ready for your CRM or analytics tools.
The journey from a generic pre-trained model to one that's production-ready involves several layers of refinement.
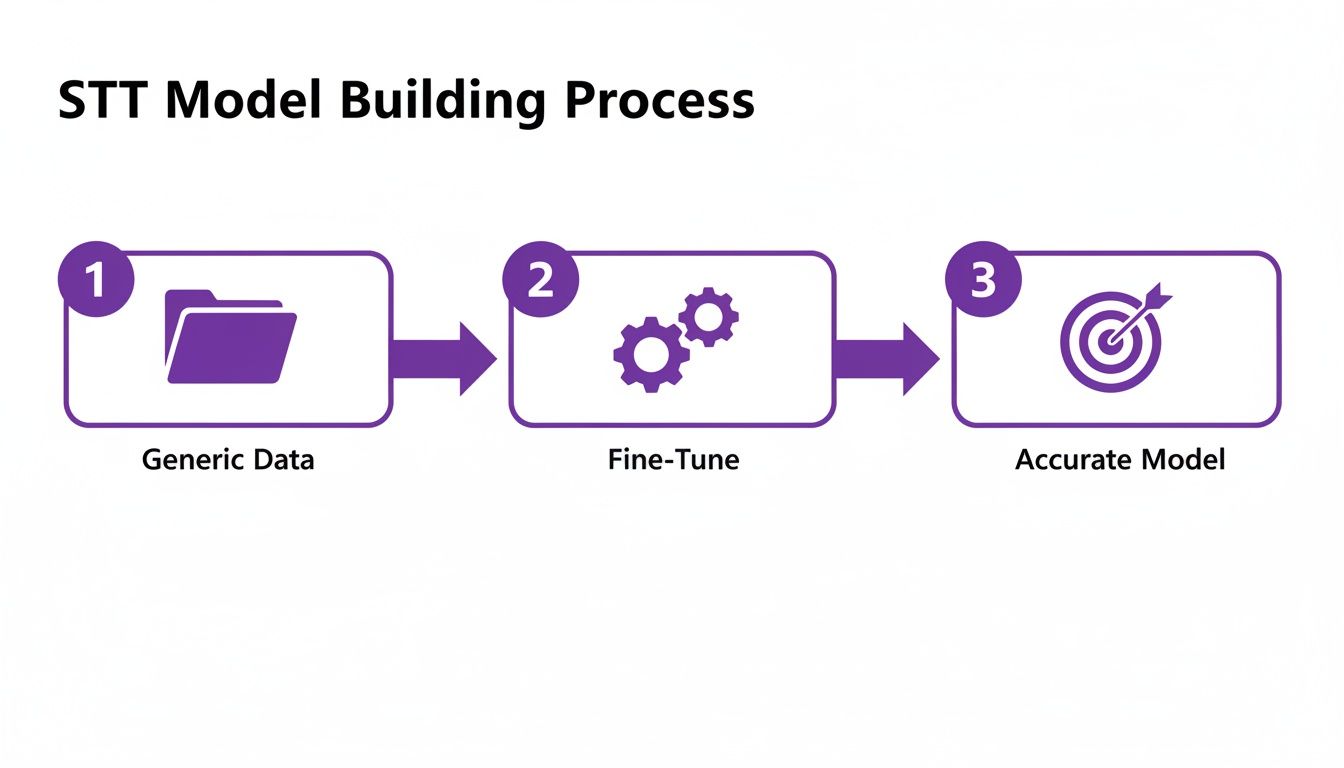
As you can see, it starts with a base model, which is then fine-tuned with your specific data to create something highly accurate and tailored to your unique conversational context.
Monitoring What Matters in Production
Once your system is live, you need to know if it's actually working. For business leaders, that means tracking more than just technical uptime. The following KPIs are essential for understanding the health, performance, and business impact of your Malayalam STT deployment.
Key Performance Indicators (KPIs) for Production STT Systems
| Metric | What It Measures | Business Impact | Target Benchmark |
|---|---|---|---|
| Word Error Rate (WER) | The percentage of words incorrectly transcribed. | Directly affects the usability of the transcript and the reliability of downstream automation. | <15% for general calls; <10% for critical applications. |
| Real-Time Factor (RTF) | How fast the system processes audio (e.g., an RTF of 0.5 means it takes 0.5s to process 1s of audio). | Determines conversational fluidity. A high RTF leads to awkward pauses and poor user experience. | <0.5 |
| Latency (First Token) | The time from when a user starts speaking to when the first transcribed word appears. | Measures the perceived responsiveness of the system. | <500ms |
| Intent Recognition Rate | The percentage of times the system correctly identifies the customer's goal (e.g., "book appointment," "check status"). | A core measure of business effectiveness. Low rates mean the agent can't solve problems. | >90% |
| Call Containment Rate | The percentage of calls fully resolved by the voice agent without human intervention. | Directly translates to cost savings and operational efficiency. | Varies by use case; aim for >70% for common queries. |
| System Uptime | The percentage of time the STT service is available and operational. | Crucial for business continuity. Downtime means dropped calls and lost revenue. | >99.9% |
Tracking these metrics gives you a clear, data-driven view of your STT system's performance and ensures your investment is delivering tangible returns.
A Case Study in Scalable Performance
The explosion of voice interactions in Indian e-commerce and travel—especially in regional languages—highlights just how critical robust STT has become. In some sectors, voice queries are growing an incredible 46 times faster than text searches.
To tackle this, Travancore Analytics built a high-accuracy speech to text Malayalam model using OpenAI's Whisper, which they fine-tuned on over 100 hours of custom Malayalam audio. This allowed them to master the language's phonetic nuances and achieve real-time speed. When deployed, voice agents using this tech can guide customers through complex processes like KYC with 97% accuracy—on par with human agents—and have boosted call connect rates to 91%. You can dive into the specifics of their approach in this detailed case study on Malayalam speech-to-text services.
For our clients, the ability to handle thousands of concurrent calls without a drop in performance is what matters. An architecture designed for scalability ensures that whether you have ten calls or ten thousand, the experience for every customer remains consistently excellent.
Ultimately, achieving this level of performance isn't just about picking the right technology. It’s about thoughtful system design that can handle peak loads and guarantee reliability. For any executive, that operational resilience is what turns a voice AI investment into a dependable asset that delivers business value day in and day out.
Measuring ROI and Ensuring Compliance
Once your speech to text malayalam system is live, the work isn't over. For any business leader, this is when the real evaluation begins: proving its value and ensuring it stays on the right side of regulations. It’s time to move past purely technical metrics like Word Error Rate (WER) and connect the dots to the business KPIs that truly matter.
The technical accuracy of your ASR model is just one piece of the puzzle. The real question for a CXO is, how does a more accurate model actually impact the bottom line? The answer comes from mapping those technical gains directly to operational improvements.
Practical Example: We saw a financial services client achieve a 5% drop in WER for their Malayalam voice agent. That might sound like a small technical win, but it translated into a 15% jump in successfully automated Know Your Customer (KYC) verifications and a 10% reduction in agent-assisted verification time. That's a direct, measurable impact on operational efficiency and risk management.
This is the kind of connection that gives you a clear, dashboard-driven view of your investment. It’s how you justify the cost and demonstrate a tangible return.
Setting Up a Continuous Monitoring Loop
To really get a grip on performance, you need a solid monitoring framework. This isn't a one-and-done audit; it's a continuous process to protect against performance decay, often called "model drift."
A core part of this is what we call a "golden dataset." This is a hand-picked collection of a few hundred audio clips representing your most common customer interactions, each with a perfect, human-verified transcript. By running this dataset through your live model on a regular schedule (e.g., weekly), you can benchmark its accuracy over time and spot any performance dips before they start affecting customers.
For a complete picture, your monitoring dashboard should cover a few key areas:
- Total Cost of Ownership (TCO): Don't just track API fees or hosting costs. Factor in everything—data management, model retraining, and the human teams needed for oversight and quality assurance.
- Business KPI Tracking: Tie the ASR's performance directly to metrics you already care about, like call deflection rates, lead qualification success, or reductions in average handling time (AHT).
- User Feedback Loops: Create channels for both your customers and your human agents to report issues. This is invaluable for finding specific phrases, accents, or scenarios where the system is failing.
Taking this well-rounded approach gives you a complete view of both the costs and the benefits, making it much easier to calculate a clear and defensible ROI.
Navigating Data Privacy and Compliance
If you operate in a regulated industry like finance or healthcare, handling sensitive customer information is your single greatest responsibility. Bringing in a speech to text malayalam system means you have new streams of data that demand careful management. Your compliance strategy is every bit as critical as your technical one.
This is particularly true in India, where data privacy laws are constantly evolving. You have to build your system with security and privacy baked in from the ground up.
Here are the absolute essentials for staying compliant:
- Data Anonymisation: Use tools to automatically find and redact or mask Personally Identifiable Information (PII). This includes names, Aadhaar numbers, and bank details, which should be scrubbed from both audio files and their transcripts before storage or analysis.
- Secure Data Storage: Enforce strict access controls and end-to-end encryption for all audio and text data, whether it's sitting on a server (at rest) or being processed (in transit).
- Data Residency: Be absolutely certain that your data storage and processing practices comply with local regulations that may require customer data to stay within India's borders.
- Purpose Limitation: Your data collection must be tightly controlled. Only process audio for the specific, defined business purposes you've already disclosed to your customers in your privacy policy.
Ultimately, the goal is to build a system that's not just accurate, but also trustworthy. By making compliance a core part of your voice AI architecture, you protect your customers, reduce your business risk, and create a solid foundation for scaling your Malayalam voice operations. This is how a simple tech tool becomes a secure, strategic asset.
Frequently Asked Questions
As you explore new technologies like speech to text in Malayalam, it’s natural to have questions about the practical side of things—cost, timelines, and how it actually performs in the real world. Here are some of the most common questions we hear from business leaders weighing up Malayalam voice technology.
What Is the Realistic Budget for a High-Quality Speech to Text Malayalam Project?
The budget for a Malayalam speech-to-text (STT) project really comes down to the path you take and the level of accuracy your business needs.
If you’re looking for a quick start, a pay-as-you-go cloud API is the fastest way to get going. You can expect costs to land somewhere between ₹0.50 to ₹1.50 per minute of audio. For a business handling around 10,000 minutes of customer calls a month, that translates to a monthly bill of ₹5,000 to ₹15,000. This approach is fast, but it can get pricey as you scale, and the accuracy might not be good enough for specific dialects or industry jargon.
For the best possible accuracy, a custom fine-tuned model is the way to go. This involves a one-time investment in collecting and labelling high-quality data. Sourcing 50-100 hours of specialised audio can cost anywhere from ₹2,00,000 to ₹5,00,000. After that initial investment, you only pay for hosting the model, which often works out to be much more cost-effective than per-minute API fees, especially at high volumes.
A fully integrated platform offers a different approach. It bundles an optimised STT engine, conversational AI, and the necessary infrastructure into a predictable fee. This makes budgeting much simpler, avoids a large upfront investment in model training, and gets you a faster return by using a system that's already been proven in the field.
How Long Does It Take to Deploy a Custom Malayalam STT Model?
The deployment timeline hinges almost entirely on one thing: data availability. If your organization already has a library of call recordings, we can often develop and integrate a custom-tuned model in as little as 4 to 6 weeks. That window covers everything from cleaning the data and transcribing it to refining the model and putting it through its paces.
If you need to collect audio from scratch, the project will naturally take longer. A project focused on gathering 100 hours of domain-specific audio, for example, would likely take 8 to 12 weeks from kick-off to full deployment.
For leaders who need to show results quickly, a hybrid strategy is often the most effective. You can go live with a high-quality general model in just 1 to 2 weeks to start seeing immediate benefits. While that's running, the custom data collection and fine-tuning can happen in the background. This allows you to switch over to a superior, bespoke model later on without any disruption to your operations.
How Does Malayalam STT Handle Different Dialects and Accents?
This is a critical point and one of the biggest reasons off-the-shelf models often fall short. A generic STT engine might do a great job with a Trivandrum accent but completely fumble a Malabar dialect, leading to high error rates and frustrated customers.
The solution is all about diversity in the training data. To build a model that is genuinely robust, you have to source audio from speakers across different regions of Kerala—think Thrissur, Kozhikode, and Ernakulam. The most powerful models are pre-trained on massive, varied datasets that already account for many of these dialectical differences from the start.
When we fine-tune a model for a client, we make sure their customer demographics are properly represented in the training data. This deliberate focus on diversity creates a model that is resilient to regional variations and delivers consistently accurate transcriptions for everyone, no matter their accent.
Can This Technology Handle Noisy Environments?
Yes, but it takes more than just a standard model to work reliably. A modern speech to text Malayalam pipeline includes advanced audio pre-processing steps specifically designed for noise reduction. These algorithms can pick out and filter common background sounds like office chatter, street traffic, or a noisy home before the audio even gets to the transcription engine.
Beyond that, we use a powerful technique during training called data augmentation. This is where we intentionally mix various types of background noise into clean audio recordings. By doing this, we effectively teach the model to focus on the human voice and ignore everything else.
For any business with agents in the field or a busy contact centre, this isn't just a nice-to-have; it's essential. It's what ensures high transcription accuracy and allows voice AI to perform reliably in the unpredictable, and often noisy, conditions of the real world.
DialNexa delivers human-like Voice AI agents that automate and scale your customer conversations. See how you can build, train, and deploy custom agents to accelerate growth by visiting us at https://dialnexa.com.
Leave a Reply