
Speech to Text in Hindi: A CXO’s Guide for 2026
If you operate in India and your voice stack still treats Hindi as a secondary language, you’re not running a growth strategy. You’re running a filter that excludes a massive share of your market. Hindi is spoken by approximately 609 million people across major states including Uttar Pradesh, Bihar, Madhya Pradesh, Rajasthan, and Haryana, and that scale is one reason Hindi speech infrastructure has become strategically important for customer-facing AI systems built for India, as shown by the 760 Hours Hindi Conversational Speech Data project.
That’s the essential framework for speech to text in hindi. This isn’t a feature discussion. It’s a board-level decision about whether your business can listen properly, route correctly, document accurately, and automate responsibly in the language your customers use.
Generic global ASR can produce demos. It often fails in the last mile. That last mile includes telephony audio, code-switching, regional accents, compliance-sensitive workflows, and messy real conversations where customers interrupt, hesitate, repeat, and switch between Hindi and English within one sentence. That’s where revenue is won or lost.
Table of Contents
- The Strategic Imperative of Hindi Speech Recognition
- Why Hindi ASR Is More Than a Translation Problem
- Evaluating Your Solution Options
- Best Practices to Maximise Hindi ASR Accuracy
- Choosing Between Real-Time and Batch Processing
- A Blueprint for Enterprise Integration
- Conclusion Your Next Steps in Voice AI for India
The Strategic Imperative of Hindi Speech Recognition
Hindi speech recognition should sit in the same strategic category as payments infrastructure, CRM discipline, and service operations. If a business depends on inbound queries, outbound calling, field sales, claims handling, collections, booking support, counselling, or lead qualification, then accurate speech to text in hindi directly affects conversion, cost control, and customer experience.
Most executive teams still underestimate the cost of misunderstanding. They look at ASR as a narrow automation layer. That’s a mistake. The transcript is often the raw material for downstream systems: lead scoring, dispute handling, QA review, compliance checks, summarisation, and agent coaching. If that input is weak, the rest of the workflow degrades.
Hindi ASR is a market access decision
A company can have strong products and still underperform because its systems listen poorly. In India, that usually happens when global voice models are deployed without local tuning. The business consequence isn’t abstract. Sales teams misclassify intent. Support teams route customers incorrectly. Analytics teams draw conclusions from noisy transcripts. Compliance teams review flawed records.
For operations leaders building an AI roadmap, the useful lens is operating efficiency. The AI implementation guide for operations leaders is worth reading because it treats AI adoption as an execution problem, not just a tooling choice. That’s the right mindset for Hindi ASR too.
Practical rule: If your business serves Hindi-speaking customers at scale, language accuracy isn’t a localisation task. It’s core operating infrastructure.
Where the board should expect return
The return usually shows up in four places:
- Better lead handling: Accurate capture of customer intent improves qualification and follow-up.
- Lower service friction: Customers don’t need to repeat themselves as often when the system understands what was said.
- Cleaner management data: Leadership gets more reliable visibility into why calls succeed, fail, escalate, or stall.
- Stronger defensibility: Companies that build India-specific voice capability create a moat that generic competitors struggle to copy quickly.
The strategic question isn’t whether speech to text in hindi works in principle. It does. The strategic question is whether your implementation is good enough for the actual nature of Indian conversations. That’s where the competitive gap opens.
Why Hindi ASR Is More Than a Translation Problem
Hindi speech recognition fails in the last mile. That is the part that determines whether you cut cost, convert more leads, and trust the downstream data in your systems.

Boards often misframe the problem. They treat speech to text in hindi as a language conversion task. The actual business issue is speech variability under Indian operating conditions: mixed Hindi and English, regional pronunciation, telephony compression, background noise, interrupted sentences, and domain terms that never appear in clean benchmark audio.
Global models usually perform well enough in demos. They break in production because Indian conversations are messy by default, not by exception. A customer says a product name in English, explains the problem in Hindi, switches to a regional phrase, then trails off because the line cuts. If your ASR stack drops meaning at that point, every system above it inherits the error.
If your team needs a technical baseline before procurement, this primer on what ASR is and how it works covers the mechanics. For enterprise buyers, the more important question is narrower: can the model preserve intent in your actual channel conditions?
The last mile decides ROI
The gap between a generic model and a business-ready Hindi ASR system shows up in a few repeated failure modes.
A support call includes:
- a regional accent shaped by local pronunciation,
- English loanwords for brands, plans, or product features,
- fan noise, traffic, or overlapping voices,
- abrupt topic shifts,
- and low-quality phone audio.
A weak model does not just miss a few words. It changes the meaning of the call. That affects ticket classification, QA scoring, escalation routing, and sales follow-up. Lead quality drops because the transcript captured the wrong need. Service cost rises because agents have to re-ask basic questions. Analytics gets polluted because management is reviewing flawed text instead of customer reality.
A poor Hindi transcript becomes bad operational data, then bad decisions.
That is the commercial difference between a pilot that looks promising and a deployment that produces measurable return.
Generic models miss what Indian businesses need most
The hardest part of Hindi ASR is preserving business meaning across real conversations. Translation is a smaller problem. Recognition under pressure is the larger one.
Specialised systems outperform because they are tuned for the patterns generic global stacks often treat as edge cases. In India, those patterns are normal. Code-switching is normal. Pronunciation drift across regions is normal. Low-bandwidth telephony is normal. Colloquial phrasing is normal. Any vendor that cannot handle those conditions is not offering a Hindi solution. It is offering a lab solution.
That distinction matters strategically. Companies that solve the last mile build an advantage that is difficult to copy quickly. They train on the right audio, tune for the right vocabulary, and connect transcripts to the right workflows. Over time, that creates better lead handling, cleaner service operations, and stronger proprietary data assets.
The board question should be sharper
Do not ask, “Does this vendor support Hindi?”
Ask a harder question. How well does this system handle Hindi in our channels, our regions, our call quality, and our business vocabulary? That is the standard that separates a feature purchase from an operating capability.
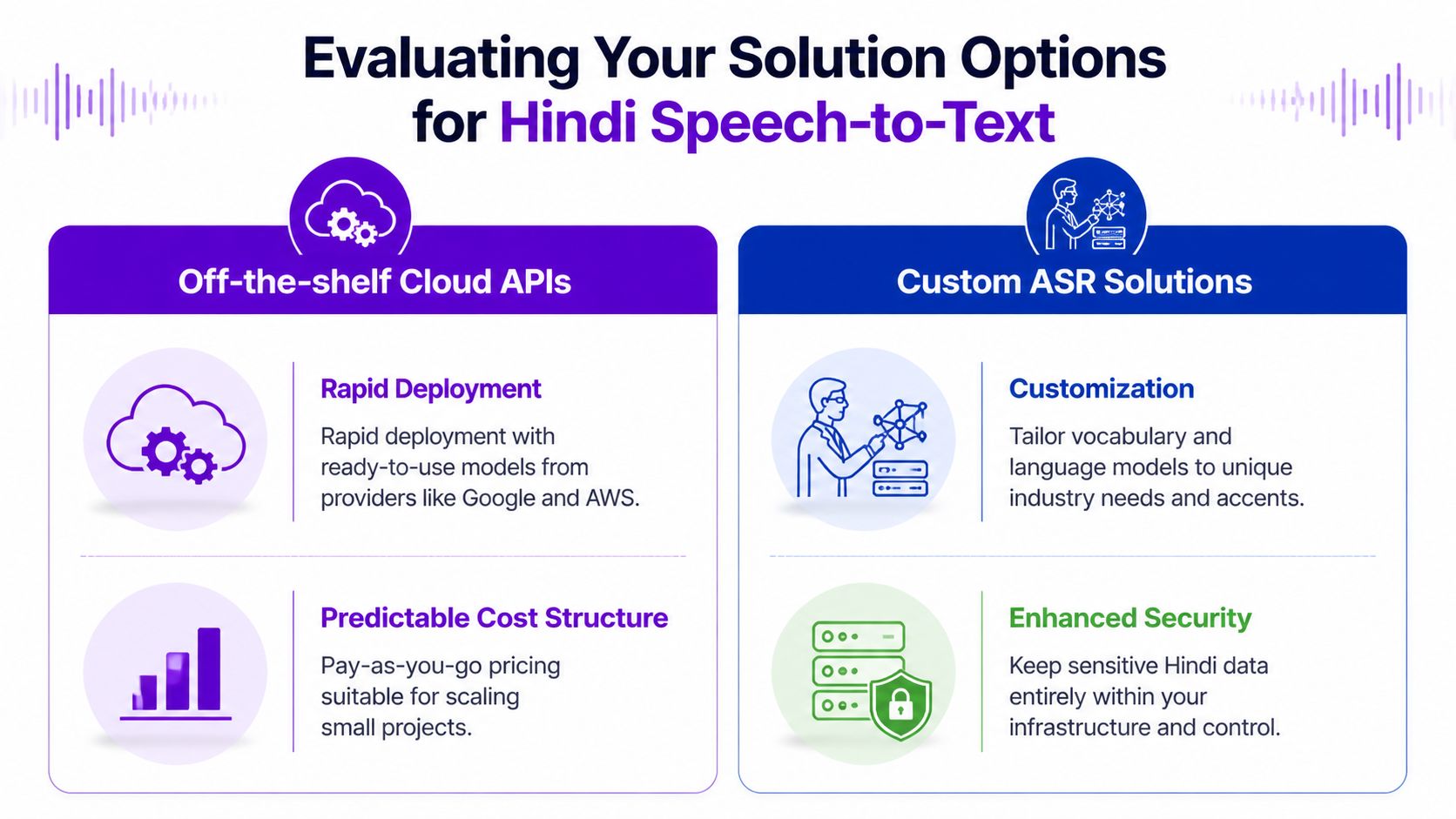
Evaluating Your Solution Options
Most companies choose between two paths. They either adopt an off-the-shelf cloud API from vendors such as Google, AWS, or Azure, or they invest in a custom-trained stack built on open models and India-specific data. Both paths can work. They serve very different strategic goals.
What boards should compare first
The wrong evaluation criterion is demo quality. The right criteria are operational fit, long-term control, and business risk.
Cloud APIs are attractive because they reduce time to launch. Product teams can test quickly, connect standard services, and get a pilot moving without building model infrastructure. For straightforward workflows, that speed matters.
Custom-trained models become attractive when Hindi accuracy materially affects revenue or compliance. BFSI, healthcare, recruitment, property sales, and multi-region support teams often land here because they need better handling of domain vocabulary, accents, and noisy calls.
Use this checklist during evaluation:
- Accuracy on your audio: Don’t accept benchmark slides. Test telephony recordings, not studio clips.
- Vocabulary control: Your system must handle product names, internal terms, and common mixed-language expressions.
- Data governance: If call data is sensitive, understand where audio and transcripts are stored and who controls them.
- Adaptability: You need a path to improve performance over time, not a static one-time setup.
- Strategic ownership: If voice is central to your customer operation, outsourcing the intelligence layer can limit future advantage.
Cloud API vs. Custom Model A Strategic Comparison
| Criterion | Cloud APIs (e.g., Google, Azure) | Custom-Trained Models (e.g., via DialNexa) |
|---|---|---|
| Deployment speed | Fast to test and launch | Slower initial rollout, stronger fit over time |
| Upfront effort | Low engineering lift | Higher setup, data, and integration effort |
| Hindi last-mile fit | Often acceptable for basic use cases | Better suited to regional nuance, noise, and domain terms |
| Control over tuning | Limited to provider options | High control over vocabulary, prompts, and adaptation |
| Data privacy posture | Depends on vendor architecture and policy | Greater control when hosted within your infrastructure |
| Strategic moat | Low, competitors can buy similar access | Higher, because tuning and workflow integration become proprietary |
| Cost profile | Simple to start, can scale with usage | Heavier setup, potentially better long-term economics for large volumes |
| Best fit | Pilots, basic transcription, low-risk workflows | Core operations, compliance-heavy use cases, conversion-critical journeys |
Boards should treat cloud APIs as a speed play and custom models as a control play.
There’s also a middle path. Some firms start with cloud infrastructure for rapid validation, then migrate high-value use cases to custom Hindi ASR once they see where transcription errors create commercial drag. That sequencing is often sensible. What isn’t sensible is assuming that a generic model and a specialised India-focused model are strategically equivalent. They aren’t.
Best Practices to Maximise Hindi ASR Accuracy
Accuracy in speech to text in hindi doesn’t come from choosing a famous model name. It comes from operating discipline. Teams that get strong business outcomes usually do a few unglamorous things well: they curate the right audio, tune for the right environments, and treat post-processing as part of the product.

Start with your own operating reality
Your model should learn from the conversations your business has. A real-estate enquiry call, a collections call, a patient booking call, and an education counselling conversation don’t sound the same. They use different phrases, pacing, interruptions, and customer emotions.
That’s why India-specific tuning matters so much. In a Vaani case study on SandLogic’s Hindi ASR work, a corpus drawn from a much larger multilingual initiative led to 366 hours and 50 minutes of clean, aligned Hindi audio-text pairs across 8 states and 51 districts, used to train a 769-million-parameter ASR model. The deployment result was a 55% WER reduction for a healthcare client and 47% WER reduction for a digital services client, compared with commercial solutions.
That’s the business lesson. Domain and geography matter. More generic isn’t better. More relevant is better.
Treat tuning as an operating discipline
Use these practices if you want reliable results:
- Build from call reality: Feed the model examples from your own telephony environment, not only clean recordings. If your customers speak over weak networks or from noisy streets, train for that reality.
- Segment by region and workflow: Hindi spoken in one market may sound materially different in another. Separate use cases where needed instead of forcing one model configuration to handle every geography equally.
- Normalise transcripts before analytics: Clean text output before it reaches CRM, QA, or summarisation tools. Otherwise, downstream automation amplifies transcription defects.
- Review noise handling carefully: Aggressive audio cleaning can remove cues the recogniser needs. This analysis of why noise reduction may hurt speech-to-text accuracy is worth sharing with your engineering and operations teams.
Don’t ask for “the best Hindi model”. Ask for the best performance on your noisiest, most commercially important call flow.
Accuracy work should be tied to business outcomes
An executive team shouldn’t approve ASR improvement work as a pure ML exercise. Tie every improvement cycle to a business metric: fewer manual transcript corrections, cleaner lead categorisation, better auditability, fewer call transfers, stronger coaching data, or more accurate post-call automation.
Teams that do this well don’t stop at transcription. They convert transcripts into action. That’s where the return appears.
Choosing Between Real-Time and Batch Processing
The choice between real-time and batch processing is more than technical housekeeping. It changes your architecture, operating cost, and service design.
Use case should drive architecture
Choose real-time processing when the transcript must shape the conversation as it happens. That includes AI voice agents, live support guidance, interactive qualification calls, and any workflow where the next response depends on what the customer just said. In those cases, latency matters because even a smart system feels broken if it answers too slowly.
Choose batch processing when the transcript supports review after the conversation ends. Compliance teams, QA managers, training leaders, and customer insights teams often don’t need instant output. They need dependable overnight or scheduled processing of large call volumes.
A simple operating rule works well:
- Use real-time for interaction and decisioning during a call.
- Use batch for analytics, audit, coaching, and archive intelligence.
- Use both if voice is central to your business and different teams need different outcomes from the same audio.
If the transcript changes the next sentence spoken to the customer, you need real-time. If it informs tomorrow’s management decision, batch is usually enough.
Many firms overbuild real-time systems for use cases that don’t need them. That wastes budget. Others underinvest in real-time for customer-facing journeys and then wonder why the experience feels robotic. Match the processing mode to the commercial role of the transcript.
A Blueprint for Enterprise Integration
Enterprise Hindi ASR should be integrated like a core business service, not bolted on as a side experiment. The winning architecture is modular. It separates capture, recognition, understanding, workflow logic, and record updates, so each layer can improve without breaking the rest of the stack.
Build a modular stack, not a brittle demo
A practical enterprise flow usually looks like this:
- Audio capture layer receives call audio from telephony, mobile apps, field devices, or support systems.
- ASR layer converts speech into Hindi text with timestamps and speaker separation where needed.
- Language processing layer classifies intent, extracts entities, summarises conversations, and flags risks.
- Business logic layer decides what to do next, such as opening a ticket, updating a lead stage, or escalating a compliance issue.
- System of record integration pushes the result into CRM, support, analytics, or workforce tools.
This modular approach matters because ASR is only one part of the value chain. The transcript has to trigger useful action.
A strong example of deployable model design comes from AI4Bharat’s IndicConformer. The IndicConformer Hindi ASR model listing describes a Conformer-Large architecture with 120 million parameters and notes that such models can reduce Word Error Rate by 15-20% on noisy Indian audio. It also states the model can be quantized to ~130MB and support real-time transcription with <500ms latency on low-cost Android phones, which makes this class of model especially relevant for field sales and support operations.
For teams comparing language rollouts across Indian markets, this reference on Marathi speech-to-text deployments and use cases is also useful because it highlights the broader architecture pattern for multilingual voice systems.
Security and workflow design matter as much as model quality
Boards often focus on recognition quality and ignore integration risk. That’s backwards. A good Hindi transcript can still create operational problems if permissions, audit trails, and routing logic are weak.
Prioritise these controls:
- Access boundaries: Limit who can hear raw audio versus who can view transcripts or summaries.
- Traceability: Keep a clear audit path from call to transcript to action taken.
- Fallback design: Route uncertain outputs to human review instead of forcing bad automation.
- Version control: Track which model version generated which transcript, especially in regulated environments.
The enterprise value of ASR appears when transcripts become safe, actionable records inside existing workflows.
If your architecture can’t support that, you don’t have an enterprise voice capability. You have a demo.
Conclusion Your Next Steps in Voice AI for India
A small drop in transcript quality can wipe out the economics of voice automation at scale. In India, that drop usually happens in the last mile. Background noise, code-switching, regional pronunciation, and inconsistent call conditions turn a strong demo into a weak operating system.
For this reason, speech to text in hindi deserves board attention. It shapes revenue capture, service cost, compliance exposure, and speed of execution. Generic global models rarely solve these India-specific gaps well enough to matter in production. Companies that close them build a defensible advantage through proprietary call data, tighter workflow design, and faster iteration on real customer interactions.
Act in this order:
- Start with a business case, not a model test. Identify the workflows where Hindi transcription errors already cost money, such as missed leads, poor QA coverage, delayed case resolution, or broken audit trails.
- Pilot on high-value, messy audio. Use real calls from sales, support, collections, or field operations. Clean lab samples will give you the wrong answer.
- Judge success by operating metrics. Measure lead conversion, agent productivity, review time, escalation accuracy, and compliance readiness. Word accuracy matters, but financial impact decides the investment.
The winners in India will not be the companies with the flashiest voice demo. They will be the ones that turn Hindi ASR into a reliable execution layer inside core workflows, then improve it faster than competitors can copy.
DialNexa Labs Private Limited helps enterprises deploy human-like Voice AI agents for qualification, support, recruitment, and presales across Indian industries. If your team wants to operationalise speech to text in hindi within real calling workflows, explore DialNexa Labs Private Limited to see how voice automation can be integrated into customer conversations without heavy setup.
Leave a Reply